之前遇到一个问题,就是首页的index.html文件 里面关联的css和js文件都是加hash值的,然后每次更新发版 index.html里面的js和css文件的hash肯定会更新 ,但是很不幸 每次用户打开的index.html文件还是上次的 html文件,也就是说因为index.html文件没有更新 导致请求的js和css还是上个版本的文件
我已经在html的head里面设置了cache-control: no-control,但是index.html文件还是没有更新,看了一下浏览器发起的request 的cache-control是no-cache,这代表的是在使用本地缓存之前会先到服务器端判断一下,这个时候如果服务器端没有开启etag机制,那就使用 Last-Modified 但是有时候 Last-Modified并不能很精确的反应修改时间 有时候可能返回的还是上次的文件,所以应该是服务器端没有开启etag机制,导致我的html文件虽然设置了不缓存,但是chrome还是以no-cache方式去到服务器端验证。。。
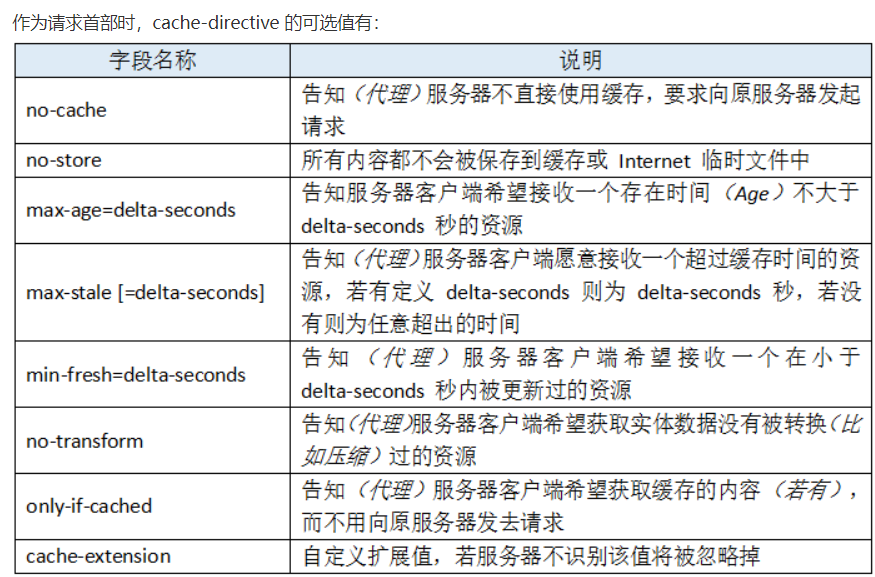
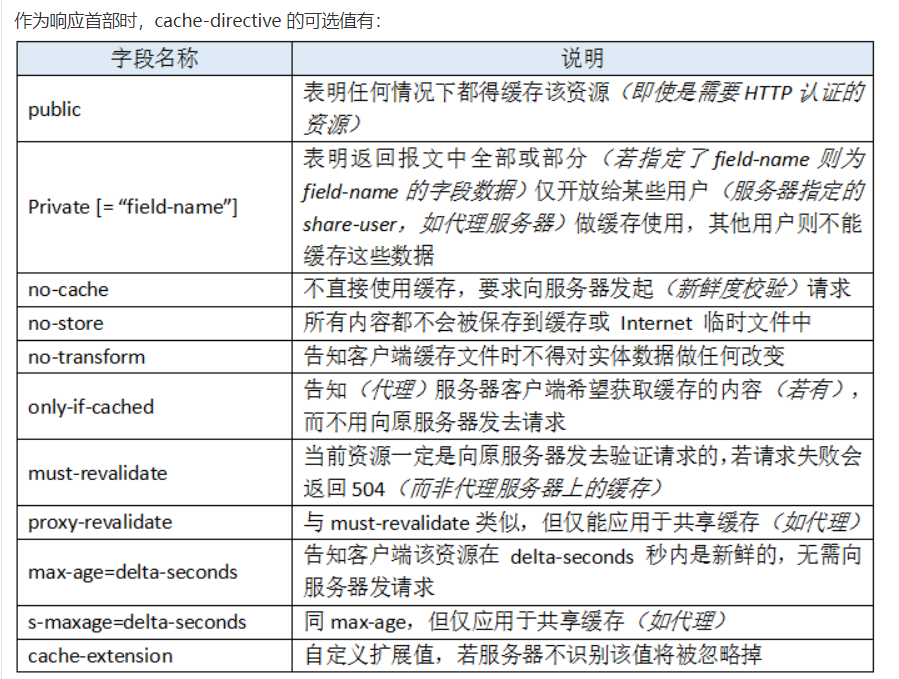
request和respones中 cache-control的no-cache的不同:
request:这个大家都知道了
response中:这个理论上是告诉客户端不要缓存,单据客户端浏览器是不是这样实现就不得而知了
如果responese中返回中明确表明缓存该文件 也就是设置max-age,那在request的时候 cache-control设置了noche,这个时候是什么样的,这个是客户端优先 所以还是会去服务器端请求一次
如果在responese中设置cache-control为no-store,那应该也是表示不缓存该文件,但是浏览器应该还是会缓存这个文件,在response中设置cache-control并不会同时应用到request中的cache-control中,
1:我之前一直理解错了,我认为只要在index.html的head中设置cache-control:no-store,下次浏览器请求的也会是cache-nostore 两者之间没有直接关系,response中的cache只是控制浏览器在发起请求前的行为
2:我理解错了第二个问题就是request的cache-control与response中的cache-control职责是不一样的,request中的cache-control意思是告诉代理服务器或者服务器我想要什么样的资源,而response中的cache-control是告诉浏览器 你需要采取什么策略缓存我的资源
3:我之前一直在纠结服务器端缓存是针对每一个客户端都缓存一套还是针对所有客户端,后来一想,如果是针对每一个客户端都去缓存一个文件,那内存迟早要充爆,所以服务器端缓存最好是针对所有客户端,意味着我们应该缓存那些通用的界面 与用户行为无关的界面
4:今天同时说request设置cache-control应该是可以覆盖response设置的cache-control策略 不知可否
参考: